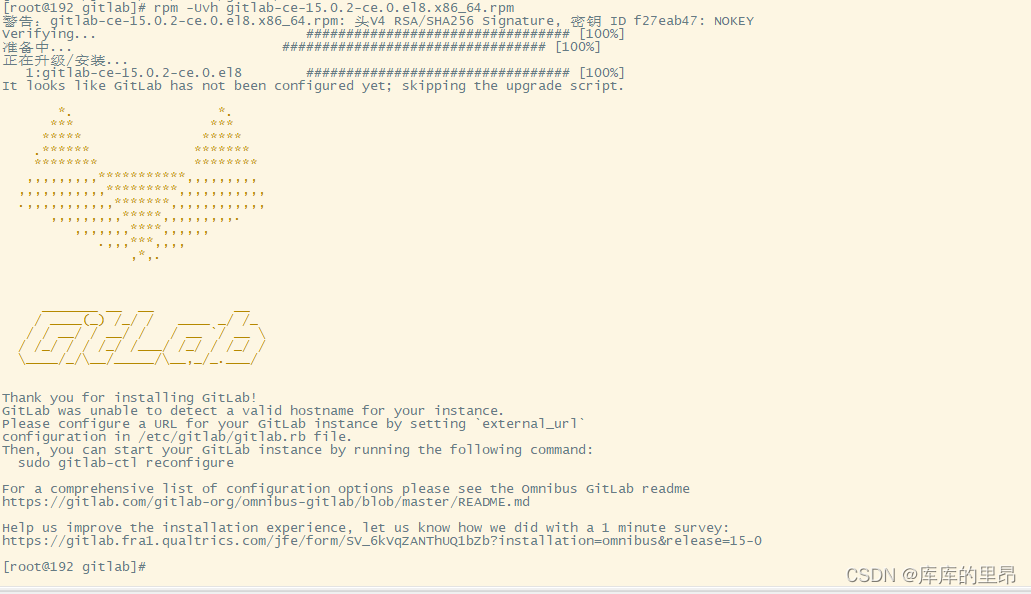
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
| #include <iostream>
#include <string>
#include <sstream>
#include <vector>
#include <map>
#include <thread>
#include <mutex>
#include <unistd.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#define Server_Port 18080 // 服务listen端口
// 定义 HTTP 请求方法
enum class HttpMethod { GET, POST };
// HTTP 请求结构体
struct HttpRequest {
HttpMethod method;
std::string url;
std::map<std::string, std::string> headers;
std::string body;
};
// HTTP 响应结构体
struct HttpResponse {
std::string status;
std::map<std::string, std::string> headers;
std::string body;
};
// 处理 HTTP 请求
// void handleRequest(const HttpRequest& req, int clientSocket) {
void handleRequest(int clientSocket) {
HttpResponse res;
// 构建 HTTP 响应
res.status = "HTTP/1.1 200 OK";
res.headers["Content-Type"] = "text/html";
res.body = "<html><body><h1>Hello, World!</h1></body></html>";
// 发送 HTTP 响应
std::ostringstream oss;
oss << res.status << "\r\n";
for (const auto& header : res.headers) {
oss << header.first << ": " << header.second << "\r\n";
}
oss << "Content-Length: " << res.body.length() << "\r\n";
oss << "\r\n";
oss << res.body;
std::string response = oss.str();
ssize_t n=write(clientSocket, response.c_str(), response.length()); // write用于将数据写入fd,返回值是成功写入的byte数
if(n<0){
std::cerr<<"Error writing response"<<std::endl;
}else{
std::cout<<"Bytes written :"<<n<<std::endl;
}
close(clientSocket);// 关闭客户端连接
}
// 启动 Web 服务器
void startWebServer() {
int serverSocket, clientSocket;
struct sockaddr_in serverAddr, clientAddr;
socklen_t addrLen = sizeof(clientAddr);
// 创建套接字
serverSocket = socket(AF_INET, SOCK_STREAM, 0);
if (serverSocket == -1) {
std::cerr << "Error creating socket" << std::endl;
exit(1);
}
// 绑定地址和端口
serverAddr.sin_family = AF_INET;
serverAddr.sin_addr.s_addr = INADDR_ANY;
serverAddr.sin_port = htons(Server_Port); // 监听端口
if (bind(serverSocket, (struct sockaddr*)&serverAddr, sizeof(serverAddr)) == -1) {
std::cerr << "Error binding" << std::endl;
close(serverSocket);
exit(1);
}
// 监听连接
if (listen(serverSocket, 10) == -1) {
std::cerr << "Error listening" << std::endl;
close(serverSocket);
exit(1);
}
std::cout << "Web server started at http://localhost:"<<Server_Port << std::endl;
while (true) {
// 接受客户端连接
clientSocket = accept(serverSocket, (struct sockaddr*)&clientAddr, &addrLen);
if (clientSocket == -1) {
std::cerr << "Error accepting connection" << std::endl;
continue;
}
// 读取 HTTP 请求
char buffer[1024];
int bytesRead = read(clientSocket, buffer, sizeof(buffer));
if (bytesRead <=0){
std::cerr << "Error reading request" << std::endl;
close(clientSocket);
continue;
}
// 解析 HTTP 请求
std::string requestString(buffer, bytesRead);
std::istringstream iss(requestString);
std::string line;
HttpRequest req;
if (std::getline(iss, line)) {
std::istringstream issLine(line);
std::string methodStr, url;
issLine >> methodStr >> url;
if (methodStr == "GET") {
req.method = HttpMethod::GET;
} else if (methodStr == "POST") {
req.method = HttpMethod::POST;
}
req.url = url;
}
while (std::getline(iss, line)) {
size_t colonPos = line.find(':');
if (colonPos != std::string::npos) {
std::string key = line.substr(0, colonPos);
std::string value = line.substr(colonPos + 1);
req.headers[key] = value;
}
}
handleRequest(clientSocket); // 处理 HTTP 请求
}
// 关闭服务器套接字
close(serverSocket);
}
int main() {
startWebServer();
return 0;
}
|